Qwen3.7-Max Tanıtıldı: Ajan Çağında Model Yarışı Yeni Eşiğe Taşınıyor

Alibaba Cloud, Qwen3.7-Max ile kodlama ajanları, MCP tabanlı iş akışları, uzun süreli otonom yürütme ve çok dilli akıl yürütme alanlarında iddialı bir model duyurdu.
Alibaba Cloud, Qwen ailesinin yeni üst seviye modeli Qwen3.7-Max ile yapay zekâ yarışındaki odağını açık biçimde "ajan çağına" taşıyor. Yeni model yalnızca daha iyi sohbet etmek veya daha doğru yanıt üretmek için değil; kod yazmak, hata ayıklamak, ofis iş akışlarını yönetmek, araç kullanmak ve saatler süren otonom görevlerde tutarlılığını korumak için konumlandırılıyor.
Bu ayrım önemli. 2024 ve 2025'te büyük dil modelleri çoğunlukla bağlam penceresi, çok dillilik ve akıl yürütme skorları üzerinden karşılaştırılıyordu. 2026'da ise soru değişti: Bir model, gerçek bir çalışma ortamında yüzlerce araç çağrısı boyunca hedefini koruyabiliyor mu? Yanlış yola girdiğinde kendini toparlayabiliyor mu? Farklı ajan çerçevelerine taşındığında performansı çökmeden devam ediyor mu?
Qwen3.7-Max'in duyurusu tam olarak bu sorulara yanıt verme iddiası taşıyor.
Modelden Çok Ajan Altyapısı
Qwen3.7-Max, Alibaba Cloud Model Studio üzerinden API ile erişilebilen kapalı kaynaklı bir model olarak sunuluyor. Duyuruda modelin dört ana alanda öne çıkarıldığı görülüyor:
- Kodlama ajanı: Frontend prototiplemeden çok dosyalı yazılım mühendisliği görevlerine kadar geniş bir alanda çalışabiliyor.
- Ofis ve üretkenlik asistanı: MCP entegrasyonları, araç kullanımı ve çoklu ajan orkestrasyonu ile kurumsal iş akışlarına uyarlanabiliyor.
- Uzun ufuklu yürütme: Yüzlerce hatta binlerce adımlık görevlerde bağlamı ve stratejiyi korumayı hedefliyor.
- Çerçeveden bağımsız performans: Claude Code, OpenClaw, Qwen Code ve özel tool-use sistemleri gibi farklı ajan iskeletlerinde tutarlı çalıştığı belirtiliyor.
Bu son madde özellikle kritik. Bir model yalnızca kendi laboratuvar ortamında iyi görünüyorsa, gerçek dünyadaki değeri sınırlı kalır. Qwen ekibinin vurgusu, modelin belirli bir harness'e ezberlenmiş reflekslerle değil, görevin kendisini çözmeye odaklanan daha genel stratejilerle yaklaştığı yönünde.
Kodlama Benchmarklarında Nerede Duruyor?
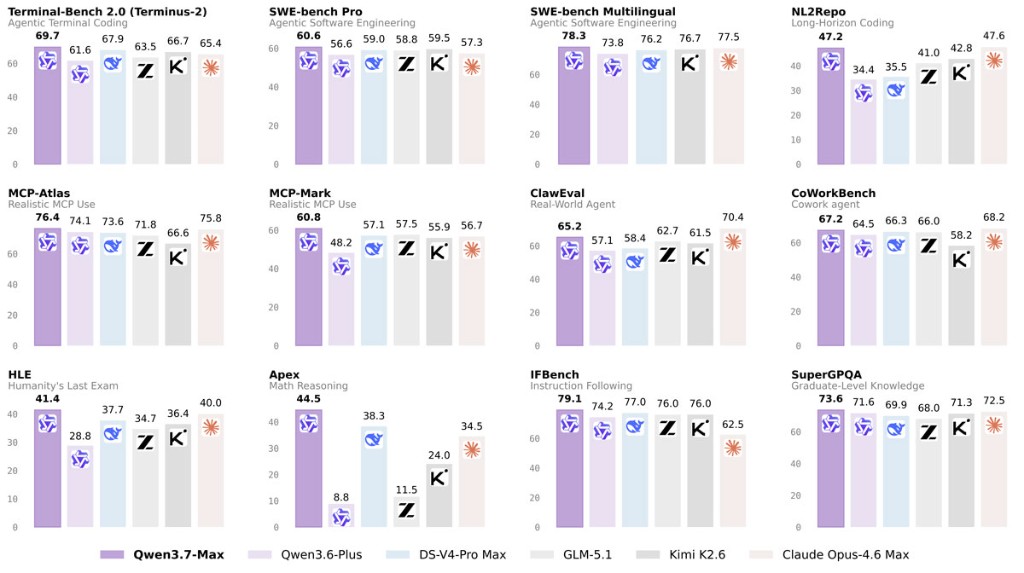
Qwen3.7-Max'in kodlama tarafındaki sonuçları, modelin doğrudan "yazılım ajanı" olarak pazarlanmasını destekliyor. Terminal Bench 2.0-Terminus'ta 69.7 skorla DS-V4-Pro Max ve Qwen3.6-Plus'ın önüne geçiyor. SWE-Pro'da 60.6, SWE-Multilingual'da 78.3, SciCode'da 53.5 ve QwenSVG'de 1608 seviyesine ulaşıyor.
SWE-Verified tarafında 80.4 sonucu, Opus-4.6 Max'in 80.8 ve DS-V4-Pro Max'in 80.6 skorlarına oldukça yakın. Burada asıl mesaj "tek bir benchmark'ta liderlik" değil; farklı kodlama ölçümlerinde sürekli üst grupta kalabilmek.
Bu tablo, Qwen3.7-Max'i özellikle şu işlerde ilginç hale getiriyor:
- Mevcut kod tabanında çok dosyalı değişiklik yapmak
- Test ve hata çıktılarından yola çıkarak iteratif düzeltme yapmak
- Frontend prototiplerini hızlıca üretmek
- Bilimsel veya teknik kodlarda akıl yürütme gerektiren görevleri çözmek
- Çok dilli yazılım depolarında bağlamı kaçırmadan çalışmak
Bugünün kodlama ajanlarında en büyük sorun çoğu zaman ilk çözümü üretmek değil, dördüncü veya beşinci düzeltme turunda bağlamı bozmadan ilerleyebilmek. Qwen3.7-Max'in iddiası da bu noktada güçleniyor.
MCP ve Ofis Otomasyonunda Güçlü Sinyaller
Genel amaçlı ajan benchmarklarında Qwen3.7-Max'in performansı daha da dikkat çekici. MCP-Mark'ta 60.8, MCP-Atlas'ta 76.4, Skillsbench'te 59.2 ve BFCL-V4'te 75.0 sonuçları açıklanmış durumda. SpreadSheetBench-v1'deki 87.0 skoru ise modelin yalnızca kod yazan bir ajan değil, ofis üretkenliği tarafında da ciddi bir aday olduğunu gösteriyor.
Bu tür benchmarklar, klasik "soru sor, cevap al" kullanımından farklı. Modelin e-posta, tablo, dosya, tarayıcı, API ve kurumsal veri kaynakları gibi araçlarla çalışması gerekiyor. MCP ekosisteminin yükselişiyle birlikte bu yetenek daha değerli hale geliyor; çünkü kurumsal yapay zekâ uygulamaları artık tek bir sohbet penceresinden çok, araçlara bağlanan iş akışı sistemleri gibi tasarlanıyor.
Qwen3.7-Max'in burada verdiği mesaj net: model, yalnızca iyi bir LLM değil; farklı araçları koordine edebilen bir "çalışma arkadaşı" olmaya aday.
35 Saatlik Kernel Optimizasyonu Neden Önemli?
Duyurunun en çarpıcı bölümü, modelin SGLang içindeki Extend Attention kernel'i üzerinde yaptığı uzun süreli otonom optimizasyon deneyi. Qwen3.7-Max, T-Head ZW-M890 PPU donanımına sahip bir ECS örneğinde, daha önce eğitiminde görmediği bir mimari üzerinde çalıştırılmış.

Anthropic CFO'sundan Çarpıcı Açıklama: Şirket Kodunun %90'ından Fazlasını Claude Yazıyor

Meta'nın Otonom Ajan Teknolojisi Manus AI, Ads Manager'a Entegre Edildi
Modelin elinde donanım dokümantasyonu, hazır örnek kernel veya önceden verilmiş profil verisi yok. Buna rağmen yaklaşık 35 saat boyunca kesintisiz çalışarak 1.158 araç çağrısı ve 432 kernel değerlendirmesi yapıyor. Süreç boyunca kod yazıyor, derliyor, profil alıyor, doğruluk hatalarını düzeltiyor ve kernel mimarisini birkaç kez yeniden tasarlıyor.
Sonuç olarak Triton referansına göre 10.0x geometrik ortalama hızlanma elde edildiği belirtiliyor. Aynı görevde GLM 5.1'in 7.3x, Kimi K2.6'nın 5.0x, DeepSeek V4 Pro'nun 3.3x, Qwen3.6-Plus'ın ise 1.1x seviyesinde kaldığı aktarılıyor.
Bu deneyin önemi yalnızca hızlanma oranında değil. Asıl kritik nokta, modelin 30 saatin üzerinde hâlâ anlamlı iyileştirmeler bulabilmesi. Çoğu ajan sistemi birkaç saat sonra hedef kaybı, bağlam çürümesi veya tekrarlayan deneme döngülerine saplanıyor. Qwen3.7-Max'in bu testte stratejisini koruyabilmesi, uzun ufuklu ajanlar için güçlü bir sinyal.
Akıl Yürütme ve Çok Dillilik Tarafı
Qwen3.7-Max yalnızca ajan benchmarklarında değil, klasik akıl yürütme ve çok dillilik testlerinde de iddialı sonuçlar paylaşıyor. GPQA Diamond'da 92.4, HLE'de 41.4, HMMT 2026 Feb'de 97.1, IMOAnswerBench'te 90.0 ve Apex'te 44.5 skorları modelin zor problem çözme tarafında üst seviyeye yerleştiğini gösteriyor.
Genel kabiliyetlerde IFBench 79.1, SuperGPQA 73.6, MRCR-v2 128k 90.4 ve QwenWorldBench 57.3 olarak açıklanmış. Çok dillilik tarafında WMT24++ 85.8, MAXIFE 89.2, MMLU-ProX 87.0 ve PolyMATH 86.5 sonuçları öne çıkıyor.
Türkçe gibi İngilizce dışı diller için bu bölüm önemli. Ajan sistemleri yalnızca kodu değil; dokümanları, e-postaları, sözleşmeleri, müşteri taleplerini ve yerel dildeki iş bağlamını da anlamak zorunda. Çok dilli performans zayıfsa, modelin kurumsal üretkenlik iddiası sınırlı kalır. Qwen3.7-Max'in burada güçlü görünmesi, global kullanım senaryoları açısından değerli.
Eğitim Stratejisi: Ortam Ölçekleme
Qwen ekibi, Qwen3.7-Max'in arkasındaki ana ilerleme motoru olarak "environment scaling" yaklaşımını öne çıkarıyor. Basitçe ifade etmek gerekirse model, yalnızca daha fazla metinle değil, daha çeşitli ajan ortamlarıyla güçlendiriliyor.
Bu yaklaşımda görev, harness ve doğrulayıcı birbirinden ayrılıyor. Aynı görev farklı araç çerçeveleriyle, farklı sürümlerle ve farklı doğrulama mekanizmalarıyla eşleştirilebiliyor. Böylece model, belirli bir arayüzün açıklarını ezberlemek yerine değişen koşullarda problemi çözmeyi öğreniyor.
Bu, ajan modelleri için kritik bir tasarım ilkesi. Gerçek dünyada her şirketin terminali, dosya yapısı, MCP bağlantıları, izin sistemi ve doğrulama süreci farklı olacak. Bir modelin üretimde değerli olabilmesi için bu çeşitliliğe dayanması gerekiyor.
Nereye Konumlanıyor?
Qwen3.7-Max, model yarışında "ben daha akıllıyım" demekten çok "ben daha uzun süre çalışabilirim" mesajı veriyor. Bu, 2026 yapay zekâ pazarındaki yön değişimini iyi özetliyor.
Artık farkı belirleyen şey sadece tek yanıt kalitesi değil. Modellerin uzun süreli görevlerde:
- hedefi koruması,
- araçları doğru sırayla kullanması,
- başarısız denemelerden öğrenmesi,
- güvenlik ve kural ihlallerini fark etmesi,
- farklı framework'lerde benzer kaliteyi sürdürmesi gerekiyor.
Qwen3.7-Max'in paylaşılan sonuçları, Alibaba'nın bu yeni rekabet alanında ciddi bir iddia ortaya koyduğunu gösteriyor. Modelin gerçek geliştirici ortamlarında, kurumsal MCP iş akışlarında ve uzun süreli otomasyon senaryolarında nasıl performans göstereceği ise asıl belirleyici olacak.
Şimdilik görünen tablo şu: Qwen3.7-Max, Qwen ailesini yalnızca açık model ekosisteminin güçlü bir oyuncusu olmaktan çıkarıp, kapalı kaynaklı üst seviye ajan modelleri liginde de görünür hale getiriyor. Eğer API erişimi, fiyatlandırma ve araç ekosistemi bu teknik iddiayı desteklerse, 2026'nın ajan altyapısı yarışında Qwen adı daha sık duyulacak.

