Claude Opus 4.8 Sahnede: Çaba Kontrolü ve Dinamik İş Akışları Ne Vaat Ediyor?

Anthropic'in yeni modeli Claude Opus 4.8, ham hızdan çok güvenilirlik ve iş birliği üzerine kuruluyor. Kullanıcıya işlem derinliğini ayarlama imkânı veren çaba kontrolü, yüz binlerce satırı paralel işleyen dinamik iş akışları ve kodda dört kat daha az hata iddiası öne çıkıyor. Tüm yenilikleri ve Mythos sınıfına dair sinyalleri ele aldık.
Anthropic, amiral gemisi model serisindeki bir sonraki adımı attı ve Claude Opus 4.8'i kullanıma açtı. Selefi Opus 4.7'nin üzerine inşa edilen sürüm, alışılmış "daha hızlı, daha güçlü" söyleminden bilinçli olarak uzaklaşıyor. Şirketin bu kez vurguladığı şey kapasite değil; modelin ne zaman emin olmadığını fark etmesi, kullanıcıyla nasıl iş birliği kurduğu ve ürettiği çıktıyı kendi kendine denetleyebilmesi.
Bu çerçeve, lansmanın iki somut yeniliğinde hayat buluyor: kullanıcıya işlem derinliğini ayarlama yetkisi veren çaba kontrolü ve Claude Code tarafına eklenen dinamik iş akışları. İkisi birlikte, modelin nasıl konumlandığına dair net bir mesaj veriyor.
Opus 4.7 ile Anthropic, ajan tabanlı görevlerde geliştiricinin müdahale ihtiyacını azaltma yönünde ilk büyük adımı atmıştı. Opus 4.8 ise o otonomiyi daha denetlenebilir ve daha güvenilir bir zemine oturtuyor. Yani buradaki hikâye, bir nesil atlama hikâyesi değil; bir önceki sürümün açtığı yolu sağlamlaştıran, kontrolü kullanıcıya geri veren bir olgunlaşma adımı.
Çaba Kontrolü: Yanıtın Derinliğini Artık Kullanıcı Belirliyor
Opus 4.8 ile gelen en pratik değişiklik, modelin bir göreve harcayacağı işlem gücünü doğrudan dışarıdan ayarlanabilir hâle getirmesi. Anthropic bunu "çaba kontrolü" olarak adlandırıyor ve mantığı oldukça sezgisel.
Düşük bir çaba seviyesi seçtiğinizde model daha az token tüketiyor, daha kısa sürede yanıt veriyor; rutin sorular ya da hızlı taslaklar için ideal. Çaba seviyesini yükselttiğinizde ise Opus 4.8 üzerinde daha uzun düşünüyor, daha fazla token harcayarak ayrıntılı muhakeme yürütüyor. Karmaşık mimari kararlar, çok adımlı analizler ya da hata ayıklama gibi senaryolarda fark burada beliriyor.
Bu yaklaşımın asıl değeri, maliyet ve kaliteyi aynı arayüzde dengeleyebilmek. Her sorgu için en pahalı modu çalıştırmak yerine, işin gerektirdiği derinliği seçebilmek demek; özellikle ölçekli kullanım yapan ekipler için token bütçesini doğrudan kontrol etmek anlamına geliyor. Tek bir modelin içinde bir "vites kolu" olarak düşünmek yanlış olmaz.
Dinamik İş Akışları: Tek Oturumda Yüzlerce Paralel Görev
Lansmanın en çok konuşulan tarafı ise Claude Code platformuna eklenen dinamik iş akışları. Geleneksel yapay zekâ asistanları genellikle tek bir görev zincirini sırayla yürütür: bir adım biter, diğeri başlar. Opus 4.8 bu doğrusal yapıyı kırıyor.
Yeni sistem, büyük ölçekli bir görevi tek bir oturum içinde planlayıp aynı anda yüzlerce alt göreve bölerek yürütebiliyor. Bu, modelin yalnızca daha hızlı çalışması değil; bir mühendislik projesini parçalara ayırıp paralel kollarda ilerletmesi anlamına geliyor.
Anthropic'in verdiği örnek bu kapasiteyi somutlaştırıyor: yüz binlerce satırlık bir kod tabanında, mevcut test altyapısını kullanarak baştan sona bir geçiş (migrasyon) yapmak. Burada kritik nokta şu; model yalnızca kod üretip bırakmıyor. Ürettiği değişiklikleri testlerden geçiriyor, sonuçları doğruluyor ve süreç boyunca kullanıcıya geri bildirim sağlıyor. Yani bir "yaz ve umut et" mantığından, "yaz, çalıştır, doğrula, raporla" döngüsüne geçiş söz konusu.
Bu özelliğin başlangıçta yalnızca Enterprise, Team ve Max planlarında sunulması da hedef kitleyi açık ediyor. Dinamik iş akışları, bireysel kullanıcıdan çok, geniş kod tabanlarını yöneten profesyonel mühendislik ekiplerine yönelik bir araç olarak konumlandırılmış.
Asıl Yatırım: Güvenilirlik ve Hata Farkındalığı
Opus 4.8'in performans tablolarının ötesinde, Anthropic'in en çok altını çizdiği konu modelin davranışsal olgunluğu. Şirkete göre yeni sürüm; güvenilirlik, hata farkındalığı ve kullanıcıyla iş birliği konularında belirgin iyileştirmeler içeriyor.
Bu, kulağa pazarlama cümlesi gibi gelse de pratik bir karşılığı var. İlk test kullanıcılarının geri bildirimlerine göre Opus 4.8, belirsiz ya da emin olmadığı sonuçları daha sık işaretliyor. Doğrulanmamış çıkarımlarda bulunma, yani kanıtı olmadan kendinden emin biçimde konuşma eğilimi ise önemli ölçüde azalmış.
Yapay zekâ modellerinin yanlış bilgiyi büyük bir özgüvenle sunması, sektörün uzun süredir uğraştığı temel sorunlardan biri. Bir modelin "bunu bilmiyorum" ya da "bu çıkarım doğrulanmaya muhtaç" diyebilmesi, çoğu zaman birkaç puanlık benchmark artışından daha değerli. Çünkü gerçek dünyada güvenin kırılması, hızdan çok bu sessiz hatalardan kaynaklanıyor.
Özellikle otonom çalışan ajanlarda bu fark katlanarak büyüyor. Saatlerce kendi başına ilerleyen bir model, yolun başında yaptığı küçük bir varsayım hatasını fark etmezse, bunun bedeli oturum sonunda devasa bir düzeltme yüküne dönüşebiliyor. Opus 4.8'in belirsizliği erken işaretleme eğilimi, tam da bu birikimli hatayı önlemeye dönük bir tasarım tercihi gibi okunuyor.

Anthropic Kârlılık Eşiğine Yaklaşıyor: Claude Büyümesi Şirketin Dengelerini Değiştiriyor

Anthropic CFO'sundan Çarpıcı Açıklama: Şirket Kodunun %90'ından Fazlasını Claude Yazıyor
Kodda Dört Kat Daha Az Hata İddiası
Bu olgunluk anlatısının en somut metriği kodlama tarafında. Anthropic, Opus 4.8'in yazdığı kodlarda hata bırakma ihtimalinin selefine göre yaklaşık dört kat daha düşük olduğunu belirtiyor.
Eğer bu iddia sahada doğrulanırsa, dinamik iş akışlarıyla doğrudan örtüşen bir tablo ortaya çıkıyor. Çünkü yüz binlerce satırı paralel işleyen bir sistemin işe yarar olması için, ürettiği her parçanın güvenilir olması şart. Düşük hata oranı olmadan otonomi, yalnızca daha hızlı biriken teknik borç demek olurdu. Opus 4.8 bu iki özelliği yan yana koyarak, "bağımsız çalışan ama daha az hata yapan ortak" konumunu hedefliyor.
Şirket ayrıca modelin güvenlik ve uyum testlerinden geçtiğini, aldatıcı veya kötüye kullanıma açık davranış oranlarının önceki sürüme kıyasla düşürüldüğünü vurguluyor.
Rakamlarla Opus 4.8
Anthropic'in paylaştığı karşılaştırma tablosu, modelin nerede öne çıkıp nerede zorlandığını net biçimde gösteriyor. Opus 4.8, ajan tabanlı kodlamada (SWE-Bench Pro) ve bilgisayar kullanımında (OSWorld-Verified) hem selefini hem de rakiplerini geride bırakırken, çok disiplinli muhakeme ve bilgi işi (GDPval-AA) skorlarında da liderliği elinde tutuyor.
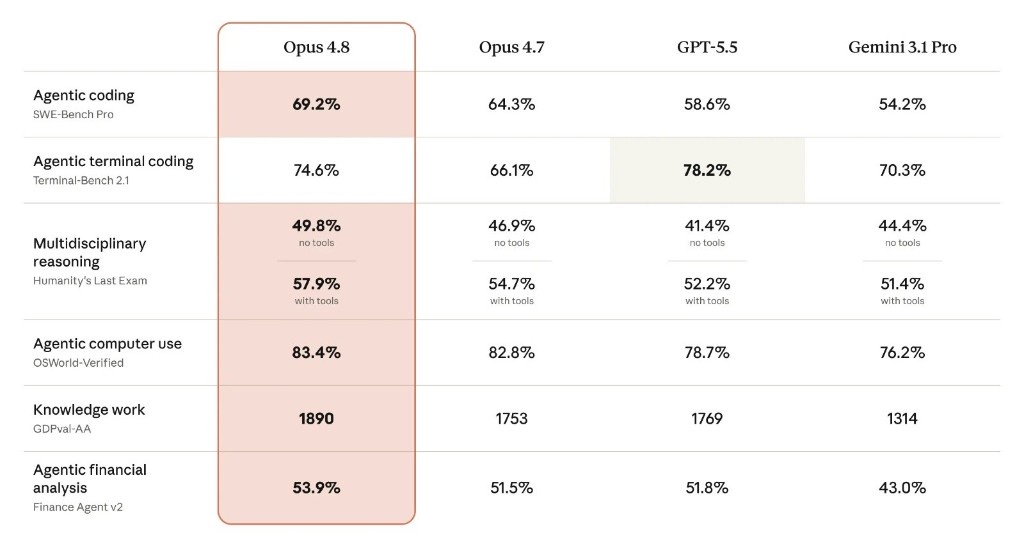
Tablo aynı zamanda dürüst bir tabloya işaret ediyor: terminal tabanlı kodlamada (Terminal-Bench 2.1) Opus 4.8 belirgin bir sıçrama yapsa da, bu kategoride GPT-5.5 hâlâ önde. Yani Opus 4.8 her ölçütte tartışmasız bir zirve değil; gücünü ajan iş akışları, uzun soluklu otonomi ve güvenilirlik tarafında topluyor.
Opus 4.8 Kimin İçin Mantıklı?
Her güncelleme gibi, Opus 4.8 de herkes için acil bir geçiş gerekçesi değil. Ancak belirli senaryolarda farkı net hissedilecek:
- Büyük ölçekli kod migrasyonları: Dinamik iş akışları, devasa kod tabanlarında testlerle doğrulanan toplu geçişler için biçilmiş kaftan.
- Maliyet hassasiyeti olan ekipler: Çaba kontrolü, her sorguya en pahalı modu harcamadan kalite-bütçe dengesi kurmayı sağlıyor.
- Riski düşük tutması gereken kullanımlar: Artan hata farkındalığı ve düşürülen hata oranı, üretime kod gönderen ekipler için güven payını yükseltiyor.
Buna karşılık, tek seferlik basit sorular ya da kısa içerik üretimi için bu yeniliklerin çoğu atıl kalacaktır.
Ufuktaki Soru: Mythos Sınıfı Ne Zaman İner?
Anthropic, geleceğe dair en dikkat çekici mesajı sona saklamış. Şirket, Opus serisinin üzerine konumlanacak yeni bir model sınıfı üzerinde çalıştığını doğruladı. Glasswing Projesi kapsamında test edilen Claude Mythos Preview modeli, özellikle siber güvenlik alanında değerlendiriliyor.
Bu daha yüksek yetenekli modellerin, kamuya açılmadan önce çok daha güçlü güvenlik katmanları gerektirdiği belirtiliyor. Tablo, geçtiğimiz dönemde gördüğümüz iki katmanlı stratejiyi pekiştiriyor: bir yanda geniş erişime açılan "genel" model, diğer yanda yeteneği zorlayan ama güvenlik gerekçesiyle dar bir çemberde tutulan "sınır ötesi" model.
Bu açıdan bakıldığında Opus 4.8, kendi başına sağlam bir yükseltme olmanın yanı sıra, daha güçlü modellerin güvenli biçimde sahaya inmesi için zemin hazırlayan bir basamak da. Çaba kontrolü ve dinamik iş akışları bugünün ihtiyacına cevap verirken, asıl merak edilen soru hâlâ açık duruyor: Mythos sınıfı yetenekler, hangi koşullarla ve ne zaman geniş kitleyle buluşacak?

