OpenAI GPT-5.5 Tanıtıldı: 'Şimdiye Kadarki En Akıllı ve En Sezgisel Model'

OpenAI, 23 Nisan 2026'da GPT-5.5 ve GPT-5.5 Pro'yu tanıttı. Terminal-Bench 2.0'da %82,7, GDPval'da %84,9 ve OSWorld-Verified'da %78,7 ile öne çıkan model, GPT-5.4 ile aynı token gecikme süresini korurken belirgin biçimde daha az token tüketiyor. Yazıda yeni yeteneklerden benchmarklara, Codex entegrasyonundan API fiyatlandırmasına kadar tüm ayrıntıları ele alıyoruz.
OpenAI, 2026 yılındaki model yarışında gazı bir türlü kesmiyor. Mart ayında GPT-5.4'ü duyurup ardından hızlıca mini ve nano türevlerini piyasaya sürdükten sonra şirket, 23 Nisan 2026'da bir adım daha attı: GPT-5.5 ve üst uç varyantı GPT-5.5 Pro resmen tanıtıldı. OpenAI, yeni aileyi "şimdiye kadarki en akıllı ve en sezgisel kullanılan model" olarak konumlandırırken, asıl vurguyu bir niteliğe yapıyor: artık görevlerin büyük kısmını modelin kendisine devredebiliyor olmak.
"Dağınık Görevi Ver, Gerisini O Halletsin" Yaklaşımı
GPT-5.5'in lansman mesajı sadelik üzerine kurulu: her adımı tek tek yönlendirmek yerine, modele çok parçalı, belirsiz ve dağınık bir brief vererek sonuca odaklanmak. OpenAI'ın resmi açıklamasına göre GPT-5.5; kullanıcı niyetini daha hızlı kavrıyor, gerekli aracı kendisi seçiyor, çıktıyı doğruluyor ve belirsizlik karşısında durmak yerine ilerlemeye devam ediyor.
Bu değişim özellikle dört alanda belirginleşiyor:
1. Ajan kodlaması (agentic coding): Kod yazmanın ötesinde; refaktör, hata ayıklama, test ve kod tabanı genelinde tutarlılık sağlama. 2. Bilgisayar kullanımı (computer use): Ekrandaki arayüzü görüp tıklayarak, yazarak, uygulamalar arasında gezinerek görev tamamlama. 3. Bilgi işi (knowledge work): Veri toplama, değerlendirme, doküman, tablo ve sunum üretimi. 4. Erken dönem bilimsel araştırma: Hipotez kurma, deney tasarımı ve analiz adımlarını tek bir akışta yürütebilme.
Bu dört alanın ortak paydası, modelin yalnızca "bir soruya yanıt verme" aşamasından çıkarak zaman içinde akıl yürüten ve eyleme geçen bir yapı hâline gelmesi.
Benchmarklar: Sayılarla GPT-5.5 Farkı
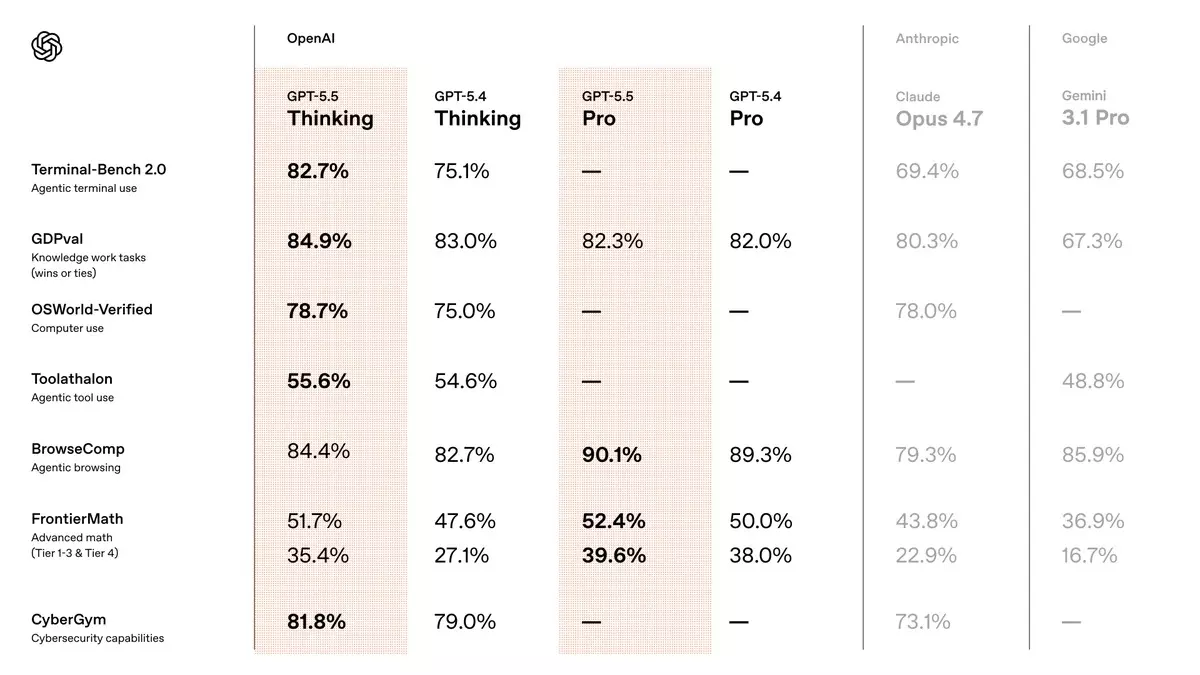
OpenAI, blog duyurusunda karşılaştırma tablosunu baskın biçimde öne çıkarıyor. Öne çıkan bazı başlıklar:
- Terminal-Bench 2.0: %82,7 (GPT-5.4: %75,1; Claude Opus 4.7: %69,4; Gemini 3.1 Pro: %68,5). Komut satırı, çok adımlı iş akışları ve araç koordinasyonu gerektiren görevlerde yeni bir yüksek skor.
- GDPval (44 meslekte bilgi işi üretimi): %84,9. GPT-5.5 Pro ise %82,3 ile yine rakiplerin önünde.
- OSWorld-Verified (gerçek bilgisayar ortamında otonom çalışma): %78,7.
- FrontierMath Tier 4: %35,4 (GPT-5.5 Pro: %39,6). İleri düzey matematik problemlerinde önemli bir sıçrama.
- SWE-Bench Pro: %58,6. Gerçek GitHub issue'larını tek seferde çözme oranı.
- Tau2-bench Telecom: %98,0 (prompt tuning olmadan). Karmaşık müşteri hizmetleri iş akışlarında neredeyse mükemmel sonuç.
- Expert-SWE (dahili): %73,1. Ortalama 20 saat insan emeği gerektiren uzun vadeli kodlama görevlerinde GPT-5.4'ü net şekilde geride bırakıyor.
Artificial Analysis'in Coding Agent Index'inde model; rakip sınır modellere kıyasla yarı maliyette aynı seviyede zekâ sunduğu iddiasıyla dikkat çekiyor. Bu, sadece "en akıllı" olmayı değil, aynı zamanda "en ekonomik en akıllı" olmayı hedefleyen bir pozisyon.
Daha Hızlı Değil, Daha Verimli
Yeni nesil modellerin tipik handikabı, kapasite arttıkça yavaşlamasıdır. GPT-5.5 bu noktayı bilinçli biçimde adres alıyor: GPT-5.4 ile aynı token başına gecikme (latency) korunuyor. Üstelik model, aynı Codex görevini önemli ölçüde daha az token tüketerek tamamlıyor. Yani hem yanıt süresi aynı kalıyor hem de toplam maliyet düşüyor.
Bunu mümkün kılan iki mühendislik hamlesi öne çıkıyor:
- NVIDIA GB200 ve GB300 NVL72 sistemleri: GPT-5.5, bu donanım yığını için ortak tasarlanıp bu yığın üzerinde eğitildi ve sunuluyor.
- Dinamik yük dengeleme: Önceden sabit parçalara bölünen istekler, GPT-5.5 tarafından yazılan yeni heuristik algoritmalarla trafik şekline göre dinamik bölünüyor. Sonuç: token üretim hızında %20'nin üzerinde kazanım. İlginç olan şu; modelin kendisi, kendisini sunan altyapıyı optimize eden kodun yazımında kullanıldı.
Geliştiriciler İçin Somut Anlatılar
Kuru benchmark rakamlarının ötesinde, OpenAI'ın duyurusunda paylaşılan erken testçi ifadeleri de modelin olgunluğu hakkında fikir veriyor. Bir şirket, uygulamasında günlerce çözemediği bir post-lansman hatasını çözmek için kıdemli mühendisini devreye sokmuş; aynı problemi GPT-5.5'e verdiklerinde model, mühendisin vardığı aynı mimari çözümü üretebilmiş. GPT-5.4 ise bu testi geçememiş.
Başka bir örnekte yüzlerce değişiklik içeren bir feature branch, bu süre içinde hızla ilerlemiş bir ana branch'e yaklaşık 20 dakikada tek seferde başarıyla birleştirilmiş. Kıdemli mühendisler, GPT-5.5'in özellikle otonomi, problemleri önceden yakalama ve açık istenmeden bile test/gözden geçirme ihtiyacını öngörme konusunda GPT-5.4 ve Claude Opus 4.7'nin üzerinde olduğunu belirtiyor.
Model yalnızca dış kullanıcılar için değil, OpenAI'ın içinde de ağırlıklı biçimde kullanılıyor. Şirket, bugün çalışanlarının %85'inden fazlasının her hafta Codex'i kullandığını söylüyor. İletişim ekibi altı aylık konuşma talebi verisini tarayıp otomatik bir Slack ajanı kurmak için, finans ekibi ise 71.637 sayfa tutan 24.771 K-1 vergi formunu incelemek için GPT-5.5 + Codex kombinasyonunu kullanmış; ikinci iş akışının bir önceki yıla göre iki hafta daha hızlı tamamlandığı paylaşılıyor.
Bilimsel Araştırmada "Ortak Bilim İnsanı"
GPT-5.5'in dikkat çekici diğer ayağı, bilimsel araştırma iş akışlarına yaptığı katkı. Genetik ve kantitatif biyolojide çok aşamalı veri analizini ölçen GeneBench ile biyoenformatik odaklı BixBench, modelin hipoteze, istatistiğe ve belirsiz veriye karşı tutumunu ölçen görece yeni testler. Her ikisinde de GPT-5.5, GPT-5.4'e belirgin fark atıyor.

Codex Cebe Geldi: ChatGPT Mobil Uygulaması Artık Kodlama Ajanlarını Yönetiyor

GPT-5.5 Instant: ChatGPT'nin Günlük Kullanım Deneyimi Nasıl Değişiyor?
Daha ilginç bir örnek ise kombinatorikte geliyor: modelin özel bir sarmalıyla çalıştırılan bir sürümü, off-diagonal Ramsey sayıları üzerine uzun süredir açık olan bir asimptotik sonuç için yeni bir kanıt üretti ve bu kanıt daha sonra Lean'de doğrulandı. Bu, modelin yalnızca kod ve açıklama değil, matematiksel argüman üretme kapasitesine dair somut bir örnek.
GPT-5.5 ile GPT-5.5 Pro Farkı
İki varyant arasındaki konumlama net: standart GPT-5.5 günlük profesyonel kullanım, araç kullanımı ve ajan iş akışları için; GPT-5.5 Pro ise daha zor, uzun vadeli ve yüksek doğruluk gerektiren görevler için. Erken testçiler Pro versiyonunu; daha kapsamlı, daha iyi yapılandırılmış ve daha tutarlı yanıtlarıyla tanımlıyor. Özellikle hukuk, finans, eğitim ve veri bilimi tarafında belirgin bir kalite sıçraması raporlanıyor.
Pro versiyonunun dikkat çeken diğer özelliği, tek seferde cevap veren bir motor olmaktan çok, bir araştırma ortağı gibi çalışıyor olması. Bir immünoloji profesörü, 62 örnek ve yaklaşık 28.000 geni kapsayan bir gen ifade veri setini GPT-5.5 Pro ile analiz etmiş; çıkan raporu "ekibinin aylar alacak işi" olarak tanımlıyor.
Erişim, Planlar ve API Fiyatlandırması
GPT-5.5'in çıkış matrisi, geçmiş modellere göre daha geniş.
- ChatGPT'de GPT-5.5: Plus, Pro, Business ve Enterprise kullanıcılarına kademeli olarak açılıyor.
- ChatGPT'de GPT-5.5 Pro: Yalnızca Pro, Business ve Enterprise planlarında erişilebilir.
- Codex'te GPT-5.5: Plus, Pro, Business, Enterprise, Edu ve Go planlarında 400K token bağlam penceresi ile sunuluyor.
- Fast mode: Token üretimi 1,5 kat hızlı; bunun karşılığı 2,5 kat maliyet.
API tarafı için tanıtım sürecinde açıklanan rakamlar:
- GPT-5.5: 1M girdi tokeni için 5 dolar, 1M çıktı tokeni için 30 dolar; 1M tokenlik context window.
- GPT-5.5 Pro: 1M girdi için 30 dolar, 1M çıktı için 180 dolar.
- Batch ve Flex fiyatlandırması standardın yarısı; Priority ise 2,5 katı.
Bu fiyatlar GPT-5.4'e kıyasla tokene göre daha yüksek görünse de, modelin görev başına belirgin şekilde daha az token tüketmesi, pratikteki toplam maliyet farkını büyük ölçüde dengeliyor.
Güvenlik: "High" Sınıf, "Critical" Değil
OpenAI, GPT-5.5'i Preparedness Framework kapsamında biyoloji/kimya ve siber güvenlik başlıklarında "High" olarak değerlendiriyor, ancak "Critical" eşiğin altında kalıyor. Modelin piyasaya sürülmeden önce yaklaşık 200 güvenilir erken erişim partneriyle test edildiği, harici red-team çalışmalarının yapıldığı ve siber özelinde daha sıkı sınıflandırıcıların devreye alındığı belirtiliyor.
İlginç bir yenilik Trusted Access for Cyber programı: doğrulanmış güvenlik uzmanlarının ve kritik altyapı sorumlularının daha az kısıtlamayla çalışabilmesi için chatgpt.com/cyber üzerinden başvuru açıldı. Kritik altyapı için özel olarak ayrılan GPT-5.4-Cyber varyantı ise savunma odaklı daha izinli bir model olarak konumlanıyor.
Değerlendirme: Model Yarışının Yeni Dengesi
GPT-5.4'ten GPT-5.5'e geçiş, sürüm numarasındaki küçük sıçramanın aksine pek çok cephede kayda değer bir adım gibi duruyor. Öne çıkan üç çizgi net:
- Ajan güvenilirliği artıyor: Modeller artık yalnızca "doğru cevap" değil, "uzun iş akışını sağlam yürütme" kriteriyle ölçülüyor; GPT-5.5 bu ölçütte rakiplerini geride bırakıyor.
- Maliyet hikâyesi değişiyor: Token başına fiyat artsa da görev başına düşen token miktarı azaldığı için reel maliyet düşüyor. Bu, kurumsal karar vericiler için kritik bir parametre.
- "Bilgisayarı kullanan model" gerçekleşiyor: OSWorld-Verified ve Tau2-bench Telecom gibi testlerdeki skorlar, modelin artık gerçekten yazılım arayüzlerinde iş görebildiğinin göstergesi.
Kısacası OpenAI, GPT-5.5 ile rekabeti yalnızca zekâ üzerinden değil; verimlilik, ajan güvenilirliği ve profesyonel iş akışlarına entegrasyon üzerinden yeniden tanımlamaya çalışıyor. Önümüzdeki haftalarda API erişimi açıldığında gerçek test; geliştiricilerin ve kurumların kendi üretim hatlarında modeli hangi işleri devrederek kullanacağı olacak. GPT-5.5'in en büyük vaadi, bu devrin hangi göreve kadar uzanabileceğini yeniden çizmek.

